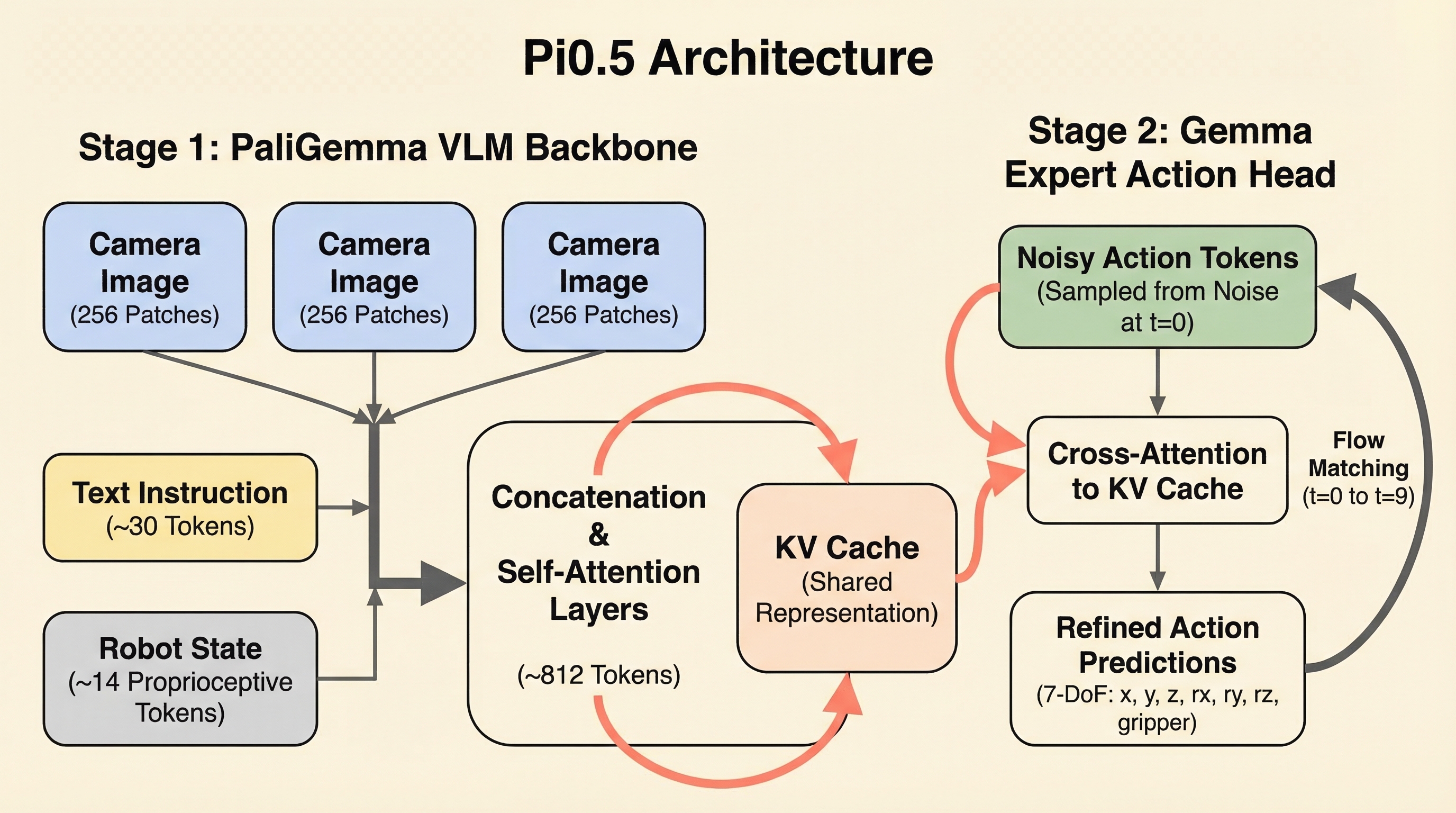
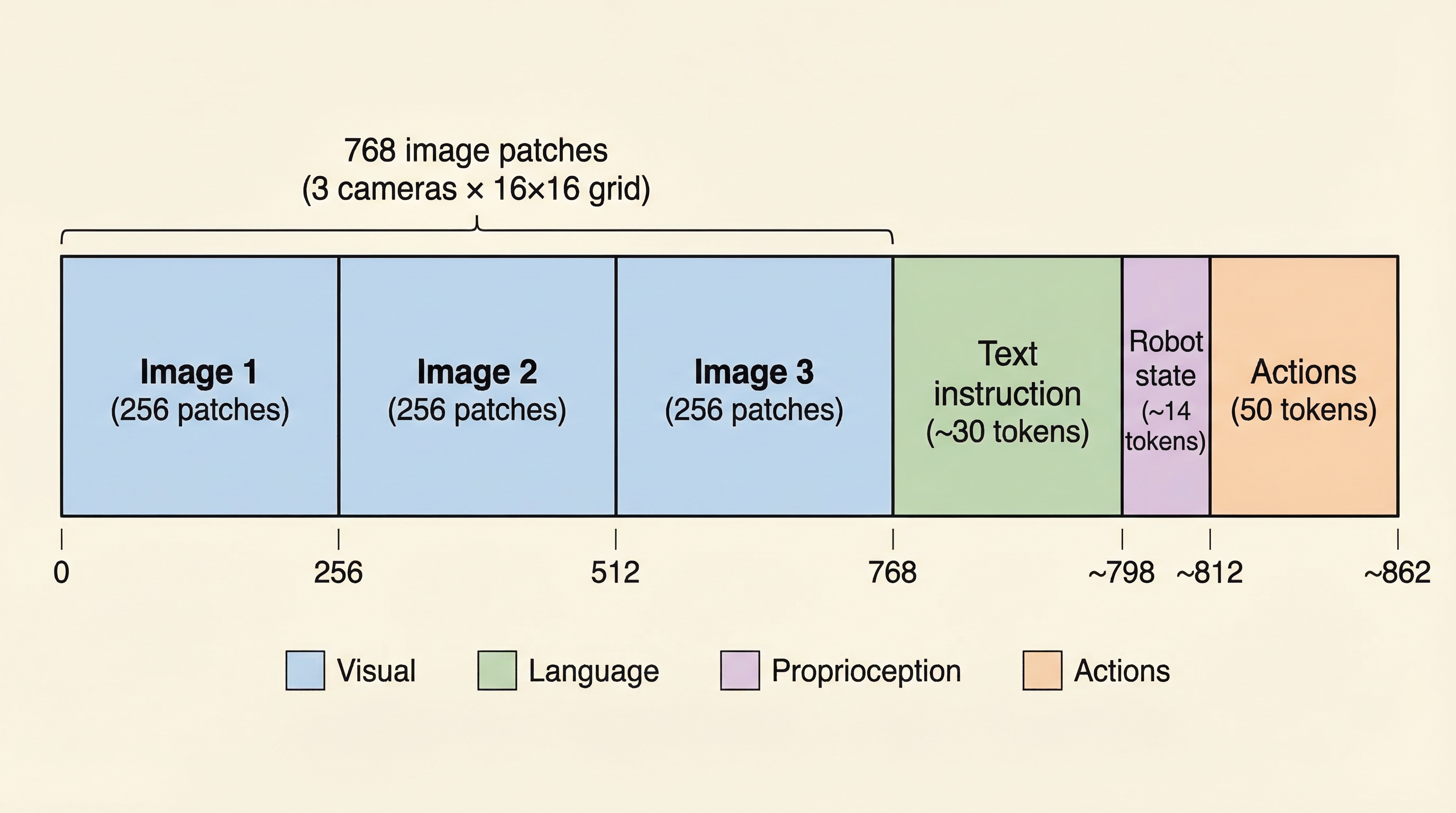
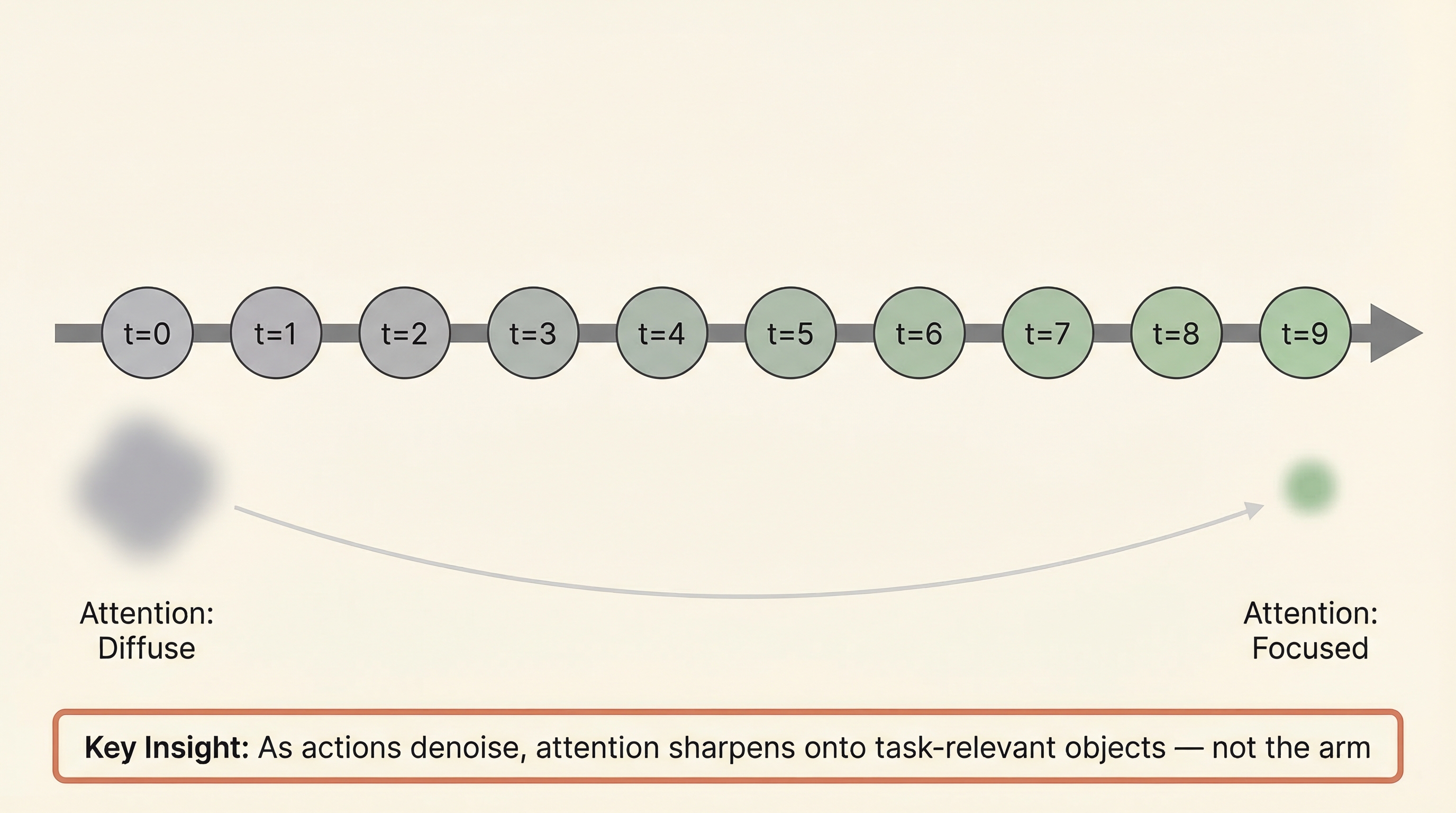
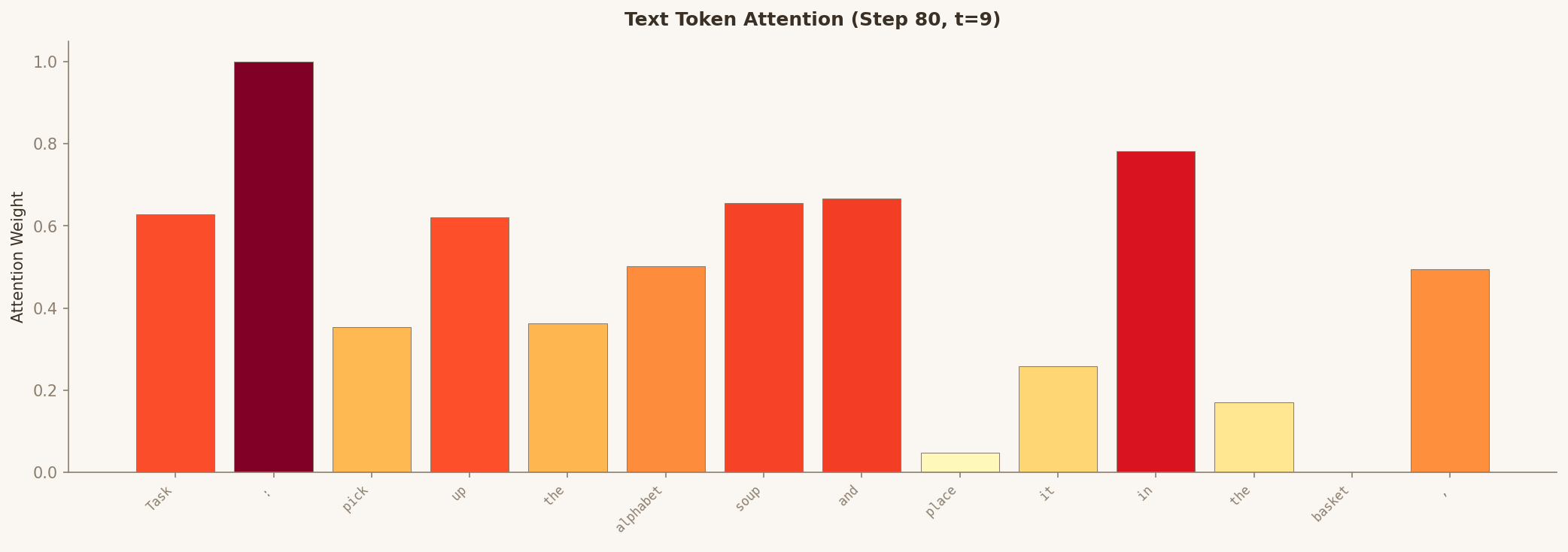
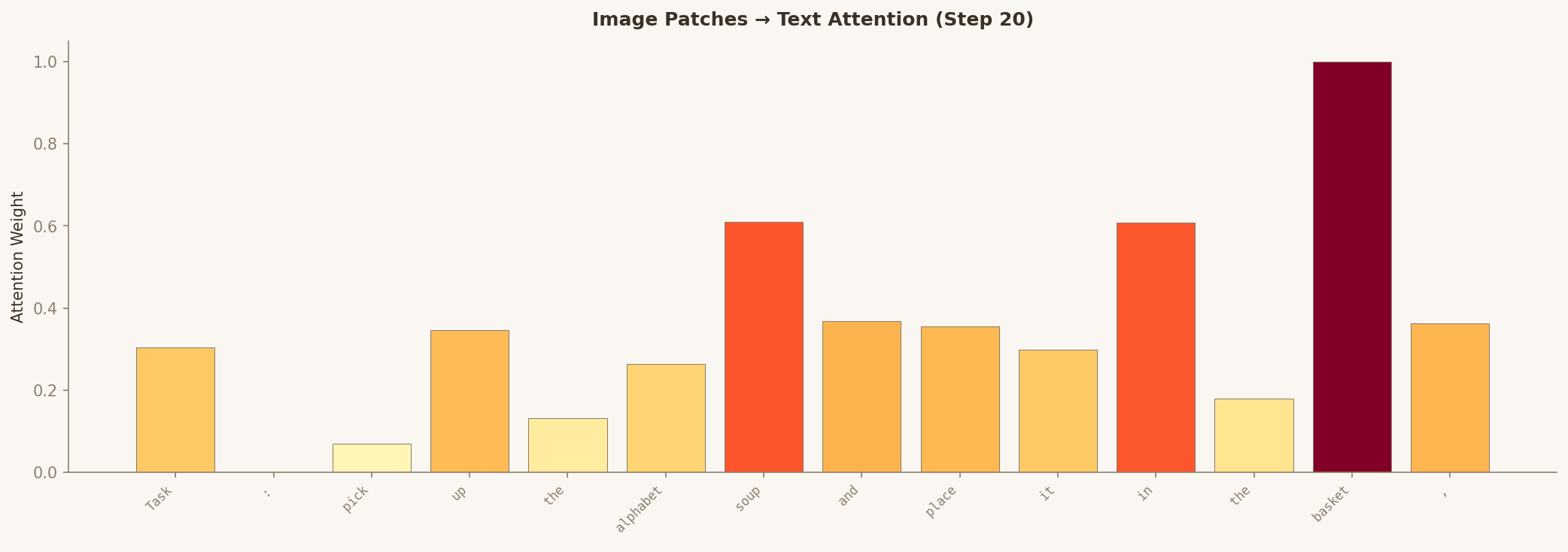
Look at the heatmap — attention concentrates on objects, not background. The bright spots reveal where the model actually looks when deciding how to move the arm.
The controls have been set to Step 0, t=9, Average heads, View 1
Now look at Head 0 specifically — individual attention heads specialize on different aspects of the scene. This head may focus on the target object.
Switched to Head 0 — compare with the average view
Switch to Head 1 — notice how it attends to different spatial regions. Each head learns a complementary visual strategy.
Switched to Head 1 — see how heads divide labor
Jump to Step 40 — the task is now in the grasp phase. Watch how attention shifts to track the soup can as the arm approaches.
Advanced to Step 40, back to average heads
At Step 100 — the arm is carrying the soup. Attention now highlights the basket destination rather than the soup. The model plans ahead.
Jumped to Step 100 — attention on the destination
Finally, switch to Camera View 2 (wrist camera) — the model gets a completely different perspective and attends to different features from this close-up viewpoint.
Switched to View 2 — wrist camera perspective
 Raw Camera View
Raw Camera View
 Attention Heatmap
Attention Heatmap